

What is ICMP? Understanding The Internet Control Message Protocol
You’ve probably heard about ICMP and if you’re just a smidge tech-savvy, you’ll probably know (at least) that it has something to do with the Internet.
ICMP is actually a protocol, much like IP, TCP and UDP (which we previously discussed and explained), so it plays quite an important role in the well-functioning of our Internet connections.
ICMP has more to do with the way connectivity issues are detected and handled, but let’s not spoil too much of our lecture. Keep on reading if you want to know what is ICMP and how it helps us maintain our connections operating at optimal levels.

What is ICMP?
The Internet Control Message Protocol, which most know by its friendlier acronym ICMP, is a protocol that’s fundamental to troubleshooting various connectivity-related issues.
This protocol is used by a wide variety of network devices, including but not limited to routers, modems, and servers to inform other network participants about potential connectivity issues.
We’ve mentioned above that ICMP is a protocol just like TCP and UDP, but unlike those two, ICMP is not generally used to facilitate the exchange of data between systems. Furthermore, it’s not frequently used in end-user network apps, unless they’re diagnostic tools.
ICMP’s original definition was sketched by Jon Postel, who contributed massively and many times to the development of the Internet, and the first standard of ICMP was published in April 1981 in RFC 777.
Obviously, the initial definition went through a lot of changes to reach the form that we’re familiar with today. The stable form of this protocol was published 5 months later than its initial definition, on September 1981, in RFC 792, and was also written by Postel.
How does ICMP work?
To put it shortly, ICMP is used for error reporting by determining whether or not data reaches its intended destination relatively quickly.
In a basic scenario, two devices are connected through the Internet and exchange information through what we call data packets or datagrams. What ICMP does is generate errors and share them with the device that sent the original data in case the packets never make it to their destination.
For instance, if you send a packet of data that’s simply too large for the router to handle, the router will first drop the packet then it will generate an error message letting the sender device that its packet never reached the destination it was heading to.
However, that’s what we would call a passive skill since there’s absolutely nothing you need to do to receive these error messages (if the need arises). As you’ll discover shortly, ICMP also has a more active utility, which you can rely on to perform various network troubleshooting operations.
As opposed to TCP and UDP, ICMP doesn’t need a device to be connected in order to send a message. In a TCP connection, for instance, the connected devices need to perform a multi-step handshake, after which the data can be transferred.
With ICMP, there’s no need for a connection to be established; a message can be simply sent in lieu of a connection. Furthermore, an ICMP message doesn’t require a port to direct the message to, compared to TCP and UDP, which both use specific ports to route information through. Not only does ICMP not require a port, but it actually doesn’t allow targeting specific ports.
ICMP messages are carried by IP packets but aren’t contained by them. Instead, they piggyback on these packets, as they’re only generated if their carrier (i.e. the IP packets) never reach their destination. More often than not, the circumstances that allowed an ICMP packet to spawn result from the data available in the failed packet’s IP header.
Since ICMP includes data of the failed packet’s IP header, network analysis tools can be used to determine exactly which IP packets failed to be delivered. However, the IP header isn’t the only type of information carried by the ICMP packet.
An ICMP packet holds the IP header, followed by an ICMP header, and the payload’s first eight bytes.
- IP header – contains details about IP version, source and destination IP addresses, the number of sent packets, the protocol used, packet length, time to live (TTL), synchronization data, as well as ID numbers for particular data packets
- ICMP header – contains a code that helps categorize the error, a sub-code that facilitates error identification by offering a description, and a checksum
- Transport Layer header – first eight bytes of the payload (transferred through TCP or UDP)
ICMP control messages
As we’ve mentioned above, when an error occurs, the values in the first field of the ICMP header can be used to identify it. These error types, along with their identifier are as follows:
- 0 – Echo Reply – used for ping purposes
- 3 – Destination Unreachable
- 5 – Redirect Message – used to indicate choosing a different route
- 8 – Echo Request – used for ping purposes
- 9 – Router Advertisement – used by routers to announce their IP addresses are available for routing
- 10 – Router Solicitation – router discovery, solicitation, or selection
- 11 – Time Exceeded – TTL expired or reassembly time exceeded
- 12 – Parameter Problem: Bad IP header – bad length, required option missing, or pointer-indicated error
- 13 – Timestamp
- 14 – Timestamp reply
- 41 – used for experimental mobility protocols
- 42 – Extended Echo Request – asks for extended Echo
- 43 – Extended Echo Reply – replies to 42 extended Echo request
- 253 and 254 – experimental
The TTL (Time to Live) field
The TTL field is one of the IP header fields that can (and often does) generate an ICMP error. It contains a value, which is the maximum number of routers that a sent packet can pass through before it reaches its final destination.
After the packet is processed by a router, this value decreases by one, and the process keeps going on until one of two things happens: either the packet reaches its destination, or the value reaches zero, which is usually followed by the router dropping the packet and sending an ICMP message to the original sender.
So it goes without saying that if a packet gets dropped because its TTL reached zero, it’s not because of corrupted data in the header or router-specific issues. TTL was actually designed to block rogue packets from obstructing connections and has resulted in the creation of a tool that is paramount to network troubleshooting: Traceroute.
ICMP usage in network diagnostics
As mentioned above, ICMP can be used with diagnostic tools to determine the well-functioning of a network connection. You may have not known what ICMP is before you read our guide, but we’re certain that you at least heard about ping, the famous network utility that lets you know whether a host is reachable or not.
Well, ping is actually one important tool that uses ICMP as its backbone. Traceroute is another good example of tools that help us diagnose and troubleshoot connectivity issues on our networks. Pathping, which is a combination of ping and traceroute, is yet another great ICMP-based tool.
Ping
Ping is a built-in Windows tool that can be accessed through CMD and is one of the most important tools that uses ICMP to troubleshoot potential networking errors. Ping makes use of two of the codes in the list above, 8 (echo request) and 0 (echo reply), to be more specific.
Here’s how two ping command examples look like:
ping 168.10.26.7
ping addictivetips.com
When you run it, ping will send an ICMP packet with a code 8 in its type field, and will patiently wait for the type 0 reply. After the reply arrives, ping will determine the time between the request (8) and its reply (0) and will return the value of the round trip expressed in milliseconds.
We already established that ICMP packets are usually generated and sent as a result of an error. However, the request (type 8) packet doesn’t need an error in order to be sent, therefore ping can also receive the reply (0) back without triggering an error.
As you probably figured out from our examples above, you can ping an IP address or a host. Moreover, ping has a plethora of additional options you can use for more advanced troubleshooting by simply appending the option to the command.
For instance, using the -4 option will force ping to use IPv4 exclusively, whereas -6 will use only IPv6 addresses. Check out the screenshot below for a complete list of options you can append to your ping command.

A common misconception about ping is that you can use it to test the availability of certain ports on targeted systems. Long story short, you can’t do that, as ICMP doesn’t do any real message exchange between hosts, unlike TCP or UDP, and doesn’t require port usage.
Port scanner apps make use of TCP or UDP packets to determine whether or not specific ports are open and accessible. The tools send TCP or UDP packets to a specific port and generate a type 3 (host unreachable) subtype 3 (destination port unreachable) ICMP message if that port is not active.
Traceroute
Much like ping, traceroute is another network troubleshooting tool that every network admin should not only have in its toolbelt but also master. What traceroute does is help you map a route of all the devices your connection bumps through until it reaches its specified destination.
So if you’re interested in finding the whole route between you and another machine, traceroute can give you exactly that information. This tool can also be used to determine whether or not there’s something wrong along the route your connection follows.
If, for instance, there’s a device on the connection path that has a hard time forwarding your packets towards their intended destination, traceroute will let you know which router gives you a delayed response (or none at all).
The way traceroute works is by sending a packet with a TTL (Time To Live) value of 0, which will be automatically dropped by the first router it encounters, as we’ve explained above in the TTL section. After dropping the packet, the router generates an ICMP packet and sends it back to traceroute.
The program extracts the packet’s source address, as well as the time it took the packet to come back, and then sends another packet with a TTL value of 1. After the second packet goes through the gateway, its TTL decreases by 1 (becoming 0) and heads to the second router, which, upon detecting the zero TTL value, drops the packet and sends an ICMP packet back to traceroute.
Each time traceroute receives an ICMP packet, it increases the TTL by one and sends it back on its track, and this operation goes on and on until the specified destination is reached, or traceroute runs out of hops. By default, Windows allocates a maximum amount of 30 hops, but you can increase that by specifying it in the command syntax.
Here’s an example of how you can run traceroute in CMD:
tracert addictivetips.com
Much like ping, traceroute has a series of options you can append to the syntax if you want to be more specific. You can force IPv4 or IPv6, but you can also skip resolving addresses to hostnames and increase the maximum number of hops to search for the target. Check out our screenshot below for a traceroute usage example and a list of all options you can use with it.
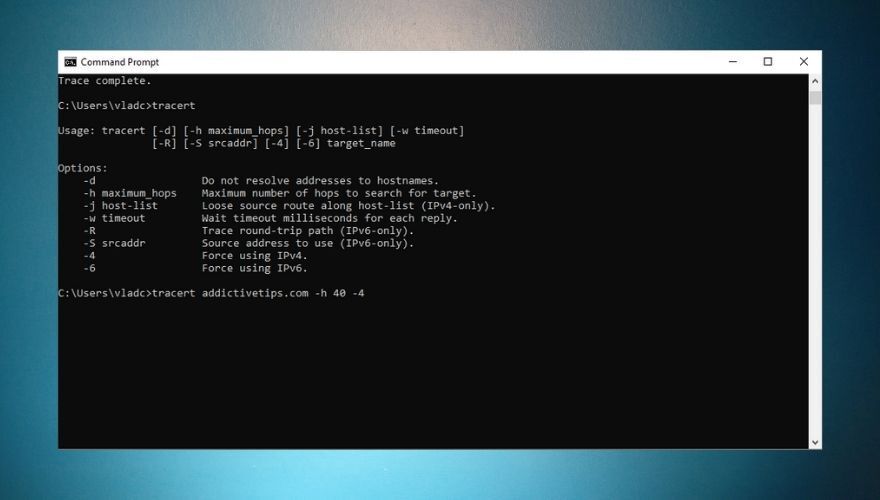
It’s worth mentioning, however, that traceroute can only provide you with real-time information. Therefore, if you’ve encountered a slowdown in your connection and want to use this tool to investigate it, you may receive misleading results as the route may have changed in the meantime.
While it’s possible to force traceroute to follow a certain path by using the -j option and adding router addresses manually, doing so implies that you’re already aware of the faulty path. This is somewhat paradoxical, since discovering the path in the first place requires you to use traceroute without the -j option.
If you’re not exactly a fan of using CLI (Command Line Interface) tools and would much rather prefer a GUI (Graphical User Interface) approach, there are many third-party software solutions for traceroute. SolarWinds’ Traceroute NG is one of the best examples we could think of. Did we mention that it’s completely free?
Pathping
As we’ve briefly mentioned above, pathping completes the trifecta of indispensable network troubleshooting tools. From a functionality standpoint, patphing is a combination of ping and traceroute, as it makes use of all three message types that the aforementioned duo exploits: echo request (8), echo reply (0), as well as time exceeded (11).
Most often, pathping is used to identify connection nodes that are affected by high latency and packet loss. Sure you could use traceroute and then ping to obtain these details, but having the functionality of both tools under a single command is far more convenient for network administrators.
One of the downsides of using pathping is that it can take quite a while to finish its inquiry (25 seconds per hop to yield ping statistics). Pathping will show you both the route to the specified destination and round trip times to it.
As opposed to ping and traceroute, pathping will ping each router in its path repeatedly, which increases its overall effectiveness. However, if it encounters a router that has disabled its ICMP functions, pathping will halt its request for information, whereas ping can still reach a router without ICMP features, and traceroute will jump to the next router in its path and display a string of asterisks for any non-ICMP routers.
Pathping is a Windows built-in tool and has been that way since Windows NT, so you can use it as you would ping or tracert: through a command line.
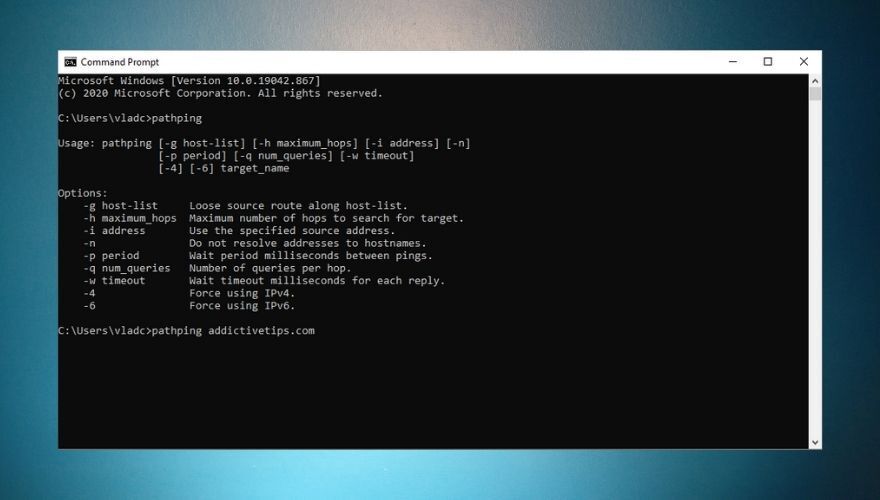
Here’s an example of how you can use pathping:
pathping addictivetips.com -h 40 -w 2 -4
The command above will show you the route to our website, as well as the round trip times to each router in the connection path. Additionally, the options we used in our example will increase the default maximum hops value from 30 to 40, add a timeout value of 2 milliseconds for each reply and force IPv4.
Check out our screenshot below for a pathping usage quick guide and a list of options you can add to the command syntax.
ICMP applicability in cyber attacks
Although ICMP’s range facilitates a lot of connectivity troubleshooting operations, this protocol can also be exploited to perform various cyber attacks. If you’ve been long enough on the Internet, you probably heard about ping flooding, DDoS, Ping of Death, Smurf Attacks, or ICMP tunnels.
While some of these attacks nowadays serve as PoC (Proof of Concept), others are still used by malicious agents to harm Internet-enabled systems or by security experts to test for vulnerabilities.
We’ll start with the most popular one, which is the ping flood (still widely used, by the way), and explain how it uses ICMP for evil.
Ping flood
Using ping to send echo requests and wait for echo replies seems quite harmless. But what if, instead of waiting for the reply, ping would just send a huge amount of ICMP echo requests? In this classical DoS (Denial of Service) attack scenario, the target device would experience severe lagging, and even connection drops if the attack is successful.
This attack is most effective if the attacker has more bandwidth than the victim, and if the victim sends ICMP echo replies to the multitude of requests it receives, thus consuming incoming as well as outgoing bandwidth.
The attacker can specify a “flood” option to the ping command, but this option is quite rare and not embedded in operating systems’ built-in tools. For instance, Windows’ ping doesn’t have a “flood” option, but there are some third-party tools that integrate this feature.
A ping flood attack can truly become catastrophic if it turns into a DDoS (Distributed Denial of Service) attack. A DDoS attack uses multiple systems to target a single one, thus overwhelming it with packets from several locations at once.
One surefire way to protect yourself against a ping flood is to disable ICMP functions on your router. You can also install a web app firewall if you need to protect a web server from such attacks.
Ping of Death
This attack involves sending a malformed ping to a target computer. In this type of attack, the sent packet will contain an amount of filler in the payload that’s too large to be processed all at once.
However, before being sent, this malicious ping will be fragmented into smaller parts, as transmitting it in its original, assembled form would be impossible for the Internet Protocol processor.
The computer that’s targeted by the Ping of Death will receive the chunks and attempt to reassemble them before sending the malicious packet to its destination application. Here’s where the damage happens: if the assembled packet is longer than the available memory in the target computer, re-assembling it might result in a buffer overflow, system crashes, and might even allow malicious code to be injected into the afflicted machine.
On the bright side, Ping of Death is no longer a novelty, as many security systems recognize it without a hiccup and successfully block it.
Smurf attack
As opposed to the previous two attack types, a Smurf attack doesn’t attack a device directly but makes use of other devices on the same network to coordinate a distributed DoS attack (a DDoS) towards a single machine.
The attacker needs its target’s IP address and the target network’s IP broadcast address. The attacker adds the victim’s IP address to ICMP packets (spoofs it) and then broadcasts them to the target’s network by using an IP broadcast address.
In response, most devices connected to the same network will send a reply to the source IP address (replaced to reflect the target’s machine), which could be overwhelmed with traffic if the network is large enough (has a huge number of connected devices).
As a result, the target’s computer can be slowed down and even rendered unusable for a given period of time, if the attack is severe enough.
As before, you can avoid a Smurf attack by simply turning off your gateway router’s ICMP capabilities. Another way you could achieve protection is by blacklisting requests coming from your network’s broadcast IP address.
Twinge attack
A Twinge attack is lead by a program that sends a flood of spoofed ICMP packets in order to harm a system. The ICMP packets are fake since they’re all using random fake IP addresses, but in reality, the packets come from a single source (the attacker’s machine).
Reportedly, the ICMP packets contain a signature that can give away the fact that the attack didn’t come from multiple sources, but was coordinated with the help of Twinge instead.
Although this attack can be disastrous if planned right, turning off ICMP on your gateway router and installing a firewall or an intrusion detection system can help you protect yourself against it.
ICMP tunnel
By default, routers only scan for ICMP packet’s headers, making it possible that packets that actually contain a lot of additional data can easily bypass detection just as long as they contain an ICMP section. This type of attack is called a ping or ICMP tunnel. Fortunately, standard ping utilities aren’t capable of tunneling through firewalls and gateways, as ICMP tunnels need to be carefully adapted to the networks they’re intended to.
On the other hand, there are numerous online resources that attackers can use and emulate such a tunnel, granting themselves free passage through private networks and machines connected to it. As before, turning off ICMP capabilities on your gateway router, using firewalls, and enforcing strict blacklisting rules can be paramount in avoiding this type of attack.
ICMP – Conclusion
All things considered, although ICMP isn’t used to exchange information between connected devices on a given network as TCP and UDP do, it still has a huge applicability range. In fact, ICMP is one of the most flexible fundamental protocols that help keep the Internet the way we know it.
Aside from its basic purpose of letting one system know when there’s a choke in its connection to another system, ICMP is the backbone of numerous troubleshooting tools such as ping, pathping, and traceroute. Unfortunately, it also helps malicious agents deliver a wide range of DoS and infiltration attacks to vulnerable machines.
